- Вправа 1.2
-
void MergeSort(std::vector<int>& a, int lo, int hi, std::vector<int>& space) { if (hi == lo + 1) return; int mid = (hi + lo) / 2; MergeSort(a, lo, mid, space); MergeSort(a, mid, hi, space); std::copy(a.cbegin() + lo, a.cbegin() + mid, space.begin() + lo); std::copy(a.cbegin() + mid, a.cbegin() + hi, space.begin() + mid); int left = lo; int right = mid; for (int i = lo; i < hi; ++i) { if (space[left] < space[right]) { a[i] = space[left++]; if (left == mid) { std::copy(space.cbegin() + right, space.cbegin() + hi, a.begin() + i + 1); break; } } else { a[i] = space[right++]; if (right == hi) { std::copy(space.cbegin() + left, space.cbegin() + mid, a.begin() + i + 1); break; } } } }
- Вправа 1.4
- Зауважимо одразу, що $C_1 = 0, C_2 = 2$. \begin{align*} C_{N+1} - C_N &= C_{\lceil \frac{N+1}{2}\rceil} + C_{\lfloor \frac{N+1}{2}\rfloor} + N + 1 - \left(C_{\lceil\frac{N}{2}\rceil} + C_{\lfloor\frac{N}{2}\rfloor} + N\right)\\ &=C_{\lceil \frac{N+1}{2}\rceil} - C_{\lfloor \frac{N}{2}\rfloor} + 1\\ &=\lfloor\lg N\rfloor + 2 \end{align*} Тут $\lfloor\lg N\rfloor$ - це сума одиничок. Вона дорівнює кількості разів, що ми маємо поділити $N$ на $2$ із взяттям найближчого меншого цілого, тобто ось за такою формулою: $$ \left\lfloor\begin{array}{@{} c @{}} \frac{ \substack{ \left\lfloor\begin{array}{@{} c @{}} \frac{ \left\lfloor\begin{array}{@{} c @{}}\frac{\lfloor \frac{N}{2}\rfloor}{2}\end{array}\right\rfloor }{2} \end{array}\right\rfloor \\ \\ \\ \dots } }{2} \end{array}\right\rfloor = 1. $$ Навіть якщо припустити, що ми відкидаємо $0.5$ після кожного ділення, то зворотній процес виглядає так: \[ (\cdots(((1\cdot 2+1)\cdot2+1)\cdot2+1)\cdots) = 2^m + 2^{m-1} + \dots < 2^{m+1} \] Отже, $\lfloor\lg N\rfloor = m$. $2$ з'являється із $(C_2 - C_1)$ - остання ітерація. Тепер ми можемо записати $C_{N}$ як телескопічний ряд: \begin{equation*} C_{N} = \sum_{k=1}^{N-1} \left(C_{k+1} - C_k\right) = \sum_{k=1}^{N-1}(\lfloor\lg k\rfloor + 2). \end{equation*}
- Вправа 1.5
-
Перевіримо нерівність для $N = 1$:
\[C_1 = 1\cdot\lceil \lg 1\rceil + 1 - 2^{\lceil \lg 1\rceil} = 0.\]
Тепер перевіримо, що якщо нерівність виконується для $N$, то вона виконується і для $N+1$. Тут у нас є два випадки:
- $\lceil \lg (N)\rceil = \lceil \lg (N+1)\rceil$, тобто $N \ne 2^n$. Тоді, \begin{align*} C_{N+1} &= (N + 1)\cdot\lceil \lg (N + 1)\rceil + N + 1 - 2^{\lceil \lg (N + 1)\rceil}\\ &= N\cdot\lceil \lg N\rceil + \lceil \lg N\rceil + N + 1 - 2^{\lceil \lg N\rceil}\\ &= C_N + \lceil \lg N\rceil + 1\\ \end{align*} Тут $\lceil \lg N\rceil + 1 = \lfloor \lg N\rfloor + 2$ і використовуючи результат вправи 1.4 рівність доведена.
- $N = 2^n$, \begin{align*} C_{N+1} &= (N + 1)\cdot\lceil \lg (N + 1)\rceil + N + 1 - 2^{\lceil \lg (N + 1)\rceil}\\ &= (N + 1)\cdot (\lg N + 1) + N + 1 - 2\cdot N\\ &= C_N + \lg N + 2\\ \end{align*} Знов-таки, використовуючи вправу 1.4 завершуємо доведення.
- Вправа 1.7
- Розглянемо варіант зі складністю $N\lg N$: \begin{align*} t_{2N} &= 2 t_N \left(1 + 1 / \lg N\right)\\ &=2N(\lg N + 1)\\ &=2N\lg (2N). \end{align*}
- Вправа 1.8
-
void merge_sort_internal( const vector<unsigned>::iterator a_beg, const vector<unsigned>::iterator a_end, const vector<unsigned>::iterator b_beg, const vector<unsigned>::iterator b_end ) { assert(distance(a_beg, a_end) == distance(b_beg, b_end)); const auto dist = distance(a_beg, a_end); if (dist <= 1) return; const auto a_mid = a_beg + (dist + 1) / 2; const auto b_mid = b_beg + (dist + 1) / 2; merge_sort_internal(a_beg, a_mid, b_beg, b_mid); merge_sort_internal(a_mid, a_end, b_mid, b_end); copy(a_beg, a_end, b_beg); auto a = a_beg; auto b1 = b_beg; auto b2 = b_mid; while (b1 < b_mid && b2 < b_end) { *a++ = *b1 < *b2 ? *b1++ : *b2++; } copy(b1, b_mid, a); copy(b2, b_end, a); } void merge_sort(vector<unsigned>& data) { vector<unsigned> buffer(data.size()); merge_sort_internal(data.begin(), data.end(), buffer.begin(), buffer.end()); } long long test(size_t size) { random_device rnd_device; minstd_rand lce(rnd_device()); uniform_int_distribution<unsigned> dist(1, numeric_limits<unsigned>::max()); vector<unsigned> v(size); generate(v.begin(), v.end(), [&dist, &lce]() { return dist(lce); }); auto start = chrono::system_clock::now(); merge_sort(v); auto end = chrono::system_clock::now(); auto elapsed = chrono::duration_cast<chrono::microseconds>(end - start); return elapsed.count(); } int main() { long long t_10_6 = test(1000 * 1000); long long t_10_7 = test(10 * 1000 * 1000); long long t_10_8 = test(100 * 1000 * 1000); double ratio = 10. * (1. + 1. / log2(10)); cout << t_10_6 << ", " << t_10_7 << ", " << t_10_8 << endl; cout << "expected ratio:" << ratio << endl; cout << "actual ratio 10^7 to 10^6:" << t_10_7 / static_cast<double>(t_10_6) << endl; cout << "actual ratio 10^8 to 10^7:" << t_10_8 / static_cast<double>(t_10_7) << endl; system("pause"); return 0; }
161000, 1776000, 20196000 expected ratio:13.0103 actual ratio 10^7 to 10^6:11.0311 actual ratio 10^8 to 10^7:11.3716
- Вправи 1.9, 1.10
- Використайте сортування підрахунком.
- Вправи 1.11
- Тут можна використати той самий підхід, що й у теоремі 1.3. $(N-1)! - $ це кількість можливих перестановок елементів для кожного розбиття. $(N+1) - $ кількість порівнянь. \[ C'_N = \sum_{i=1}^N\left(C'_{i-1}+C'_{N-i}\right)+(N-1)!(N+1) \]
- Вправи 1.12
-
Вибираючи елементи в праву і ліві частині розбиття ми порівнюємо елементи лише з опірним елементом $v$ і ніколи між собою. Через ми ніяк не впорядковуємо елементи в кожній з частин. Якщо замість
j = hi;ми напишемоj = hi + 1;, то першим же обміном в цикліwhile (true)ми перенесемо елемент $v$ в ліву частину розбиття, і всі елементи перед ним менші ніж цей елемент. Наприклад, \[3,5,2,11,7,10,12,9\] розбиваємо на \[3,5,2,9,7,10\quad\mbox{і}\quad12\] і в лівій частині ми бачимо, що до першої $9$ всі елементи менше ніж $9$.
- Вправа 1.13
-
Під час розбиття ми не робимо порівнянь між елементами лівого і правого підмасивів, таким чином ніяк не впорядковоючи їх, тому ці підмасиви також випадкові перестановки. Якщо ж ми ініціалізуємо правий вказівник
j = hi + 1, то умоваwhile (v < a[--j])завжди хиба на першій ітерації зовнішнього циклу. Через це ми точно знаємо, що до елемента зі значенням $v$ всі елементи менші ніж він, а за ним вже можуть бути й більші. Тобто перестановка невипадкова. $$1,3,9,5,7,2,4$$ $$1,3,4,5,7,2\quad9$$ Тут $v = 4$, зауважте, що ліворуч всі елементи до $4$ менші ніж $4$.
- Вправа 1.14
- \begin{align*} A_N N &= N + 2\sum_{1\le j\le N} A_{j-1}\\ A_{N-1}(N-1) &= N-1 + 2\sum_{1\le j\le N-1} A_{j-1}. \end{align*} Віднімемо друге рівняння від першого. \begin{align*} A_N N - A_{N-1}(N-1) &= 1 + 2A_{N-1}\\ A_N N - A_{N-1}(N+1) &= 1 \end{align*} Розділемо на $N(N+1)$. \begin{align*} \frac{A_N}{N+1} - \frac{A_{N-1}}{N} = \frac{1}{N(N+1)} \end{align*} Тепер двічі використаємо прийом телескопічного ряду. \begin{align*} \frac{A_N}{N+1} - \frac{A_0}{1} &= \sum_1^N\frac{1}{k(k+1)}\\ \frac{A_N}{N+1} - \frac{A_0}{1} &= \sum_1^N\left(\frac{1}{k}-\frac{1}{k+1}\right)\\ \frac{A_N}{N+1} - \frac{A_0}{1} &= \frac{1}{1}-\frac{1}{N+1}\\ \end{align*} Якщо $A_0 = 0$, то \begin{equation*} A_N = N \end{equation*} Дуже цікавий результат, і його нескладно перевірити.
- Вправа 1.15
-
Нас цікавить скільки обмінів відбулось в тілі цього циклу:
Фактично нам потрібно знайти математичне сподівання кількості обмінів. На останню позицію в масиві рівноймовірно може потрапити будь-який елемент. Позначимо його позицію в відсортованому масиві через $p$, а сам елемент через $v$. Отже, у нас є $N-p$ елементів більше ніж $v$ і $p-1$ елементів менше ніж $v$. Імовірність натрапити на елемент менший ніж $v$ становить $\frac{p-1}{N}$ і більший - $\frac{N-p}{N}$. Відповідно, щоб зустріти елемент більший ніж $v$ ми в середньому пройдемо $\frac{N}{N-p}$, а менший - $\frac{N}{p-1}$. В цьому циклі ми маємо зробити $N$ порівнянь, останній елемент порівнюється двічі. Отже, \begin{align*} \frac{1}{N}\sum_{p=1}^N\frac{N}{\frac{N}{N-p}+\frac{N}{p-1}} &= \sum_{p=1}^N\frac{1}{\frac{N(N-1)}{(N-p)(p-1)}}\\ &=\frac{1}{N(N-1)}\sum_{p=1}^N(Np - N - P^2 +p)\\ &=\frac{1}{N-1}\left(-N + \frac{N(N+1)}{2} - \frac{1}{N}\sum_{p=1}^N p^2 + \frac{N+1}{2}\right)\\ &=\frac{1}{N-1}\left(-N + \frac{N(N+1)}{2} - \frac{(N+1)(2N+1)}{6} + \frac{N+1}{2}\right)\\ &=\frac{1}{N-1}\frac{N^2-3N+2}{6}\\ &=\frac{N-2}{6}. \end{align*}
while (true) { while (a[++i] < v) ; while (v < a[--j]) if (j == lo) break; if (i >= j) break; t = a[i]; a[i] = a[j]; a[j] = t; }
- Вправа 1.16
- \begin{align*} T_N &= \frac{1}{N}\sum_{k=1}^N\left(T_{k-1}+T_{N-k}\right)\\ & = \frac{2}{N}\sum_{k=0}^{N-1}T_k \end{align*} Тепер розглянувши $NT_N - (N-1)T_{N-1}$ ми отримуємо: \begin{align*} T_N &= \frac{N+1}{N}T_{N-1}\\ &= \frac{N+1}{N}\cdots\frac{5}{4}T_3\\ &= \frac{N+1}{6} \end{align*} Базовий випадок: \[ T_3 = 1/3(1 + 1) = 2/3 \]
- Вправа 1.17
- \begin{align*} C_N &= N+1 + \frac{1}{N}\sum_{j=1}^{N}(C_{j-1}+C_{N-j})\\ &= N+1 + \frac{2}{N}\sum_{j=0}^{N-1}C_j\\ &= N+1 + \frac{2}{N}\left(\sum_{j=M+1}^{N-1}C_j + \frac{1}{4}\sum_{1}^M j(j-1)\right) \end{align*} \begin{align*} NC_N - (N-1)C_{N-1} &= (N+1)N - N(N-1) + 2C_{N-1}\\ NC_N - (N+1)C_{N-1} &= 2N \end{align*} Використовуємо принцип телескопа складаємо всі рівності від $\frac{C_N}{N+1} - \frac{C_{N-1}}{N}$ до $\frac{C_{M+1}}{M+2} - \frac{\frac{1}{4}M(M-1)}{M+1}$: \[ \frac{C_N}{N+1} - \frac{1}{4}\frac{M(M-1)}{M+1} = 2 (H_{N+1} - H_M) \] \[ C_N = \frac{1}{4}(N+1)\frac{M(M-1)}{M+1} + 2(N+1)(H_{N+1} - H_M) \]
- Вправа 1.18
- \begin{align*} C_N &\approx \frac{1}{4}N\frac{M(M-1)}{M+1} + 2N(\ln(N+1) - \ln M)\\ &\approx 2N\ln N + N\left(\frac{1}{4}\frac{M(M-1)}{M+1} - 2 \ln M\right) \end{align*} Мінімуму функція сягає коли $M = 8$.
- Вправа 1.19
-
Кількість порівнянь, яку виконує швидке сортування $\approx 2N\ln N - 1.846N$. При переході з $17$ на $18$, $f(M)$ перестрибує $-1.846$.
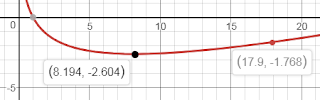

- Вправа 1.20
-
Це те саме, що запитати скільки урн міститиме більш ніж одну кулю якщо покласти $10^4$ куль в $10^6$ урн. Досить просто це можна порахувати за допомогою індикаторних змінних.
Нехай $X_i=1$ якщо $i$-та урна містить більше ніж одну кулю і $0$ якщо ні. Тоді $E[X_i]=1−P_0−P_1$, де $P_J$ позначає ймовірність, що ця урна містить рівно $j$ куль.
\begin{align*}
P_0 &= \left(\frac{U-1}{U}\right)^B,\\
P_1 &= U\left(\frac{U-1}{U}\right)^{B-1}\left(1-\frac{U-1}{U}\right).
\end{align*}
Розрахунок в Matlab:
І невеличка симуляція:
>> U = 10^6; >> B = 10^4; >> p = (U-1)/U; >> (1 - p^B - B*p^(B-1)*(1-p))*U ans = 49.663
Вивід не значно відрізняється від отриманого теоретичного результату:const int U = 1000 * 1000; const int B = 10 * 1000; std::random_device rd; std::mt19937 gen(rd()); std::uniform_int_distribution<> dis(0, U-1); double mean = 0; const int roundsCount = 100; for (int round = 0; round < roundsCount; ++round) { unordered_map<int, int> file; for (int i = 0; i < B; ++i) { ++file[dis(gen)]; } int duplicated = 0; for (auto& el : file) { if (el.second > 1) { ++duplicated; } } mean += duplicated / static_cast<double>(roundsCount); } cout << mean << endl;
48.87
- Вправа 1.21
- Чим з меншого діапазону вибираються елементи масиву, тим швидше працює швидке сортування. В крайньому випадку, якщо всі елементи однакові, то розбиття відбувається навпіл і алгоритм працює найшвидше.
- Вправа 1.22
- Вправа 1.23
- Реалізація наведена в цій частині завжди ділить навпіл, і виконує порівняння лише під час злиття і кількість порівнянь не залежить від входових даних. Тому дисперсія дорівнює $0$.